274 commits, 50+ PRs, 4 packages: anatomy of a v2 breaking change that landed alive
The PRD documented 9 breaking-change patterns. The reality was 26+. This is what I learned coordinating a major version bump across 4 repositories and 3 simultaneous packages.
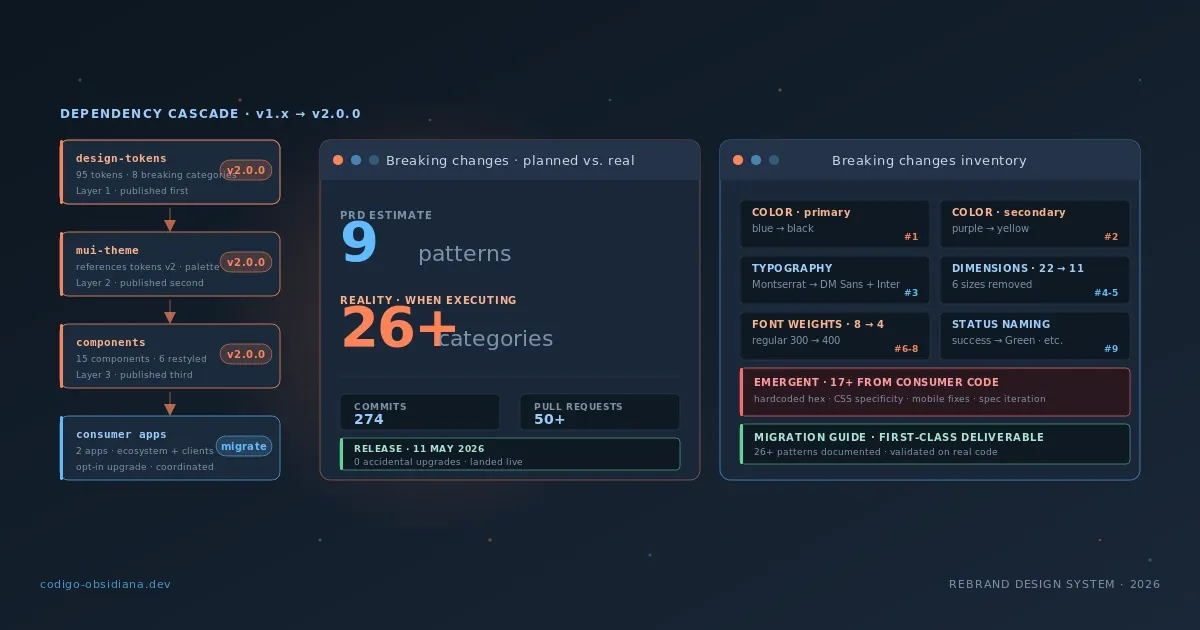
On May 11, 2026, we merged a feature branch with 274 commits, 50+ PRs, and changes across 4 simultaneous repositories. The tokens package hit v2.0.0. The theme package hit v2.0.0. The component library hit v2.0.0. And a fourth assets package bumped from 1.0.0 to 1.1.0.
The PRD I wrote in March documented 9 breaking-change patterns. The reality was 26+ distinct categories.
That wasn't a planning failure. It was an honest snapshot of what you see when you put a real system under the lens of a major change.
The anatomy of a chained breaking change
A breaking change in a monorepo with nested dependencies isn't an event, it's a sequence. The order matters as much as the content.
In our case, the dependency graph looked like this:
tokens package v2.0.0
│
▼
theme package v2.0.0
│
▼
component library v2.0.0
│
▼
┌───────┴────────┐
│ │
main app client / ecosystem apps
Each layer of the graph consumes the previous one. That means that if you publish the theme before having the tokens stable, the theme builds on sand. If you update the components before the theme is ready, every component override touching the palette is going to produce incorrect results.
The operational rule was simple: no layer could be considered ready until the layer below it was published and verified.
In practice, this meant three serial builds across different weeks, and a single integration week at the end. Consumer apps didn't touch the v2 packages until the three base packages were published and we had verified Storybook rendered correctly.
Why the major version bump makes everything more manageable
Publishing as v2.0.0 (not 1.2.0 or 1.1.0-beta) was a communication decision, not just a semver one.
With a major bump, the package ecosystem gives you a safety net by default: ^1.x.x doesn't resolve to 2.0.0. No consumer app updates on its own. Nobody receives the change without asking for it. The migration is opt-in and coordinated.
If we had published as a minor (1.x.0), the update would have been automatic in any repo with ^1.0.0, and a primary palette change from blue to black would have appeared in production without warning. With major, the barrier is intentional.
What the plan captured (and what it didn't)
The PRD listed 9 breaking-change patterns. These are the ones I saw coming from the architecture:
| # | Pattern documented in the PRD |
|---|---|
| 1 | Primary color: blue → black |
| 2 | Secondary color: purple → yellow |
| 3 | Font: Montserrat → DM Sans + Inter |
| 4 | 6 dimensions removed (28–80px) |
| 5 | 2 spacings removed (64px, 80px) |
| 6 | radius.4 (24px) removed |
| 7 | 4 font weights removed (100, 200, 800, 900) |
| 8 | weights.regular: 300 → 400 |
| 9 | Status group renaming (success→Green, warning→Yellow, etc.) |
What the PRD couldn't see was the actual state of the consumer repos. Until we started actively searching for where tokens, theme, and components were being consumed, we didn't have visibility on the full delta.
The real inventory: 26+ categories
The 6 categories that emerged during execution:
1. Component migrations (5 sub-categories) Button, Alert, TextField, Select/Autocomplete, DatePicker, Snackbar, Tabs: all had local implementations in the consumer repos that had to be replaced by the centralized library versions. It wasn't just updating styles — it was consolidating duplicated code that had evolved independently.
2. Token and color replacements (6+ cases) Hardcoded brand colors inside features for payments, clients, and collections. Each one was a manual finding during the migration, not during the audit. The token audit we did months earlier had captured references to design token variables, but not the hex codes written directly into stylesheets. The search was literal: grep for the hex of the previous primary blue, grep for the hex of the secondary purple, and then visual review of the results. There's no elegant way to do it — you just have to do it.
3. Typography system (4 cases) The new font stack was applied globally through the theme, but there were specific flows (auth, registration) that had v1 typography tokens referenced directly. Each one required an explicit replacement.
4. Spacing and layout (4+ cases)
The size prop on wallet components was removed. min-width constraints that the previous theme implicitly imposed were left exposed when the theme changed. The navbar and sidebar needed alignment with the new Figma specs — changes that weren't visible in the design system in isolation, but were obvious when viewing the full product with the new theme applied. None of these were documented API violations — they were side effects of the theme change that only reveal themselves in real-world usage.
5. Asset migration to CDN (6 cases)
The Lottie animations were replaced by static SVGs plus CSS animation — with measurable bundle savings. Error state icons migrated to the CDN. The logo controller component was refactored to read the VITE_CDN_URL environment variable. 10 legacy images without active use were removed.
6. Brand and domain (2 cases) References to the previous domain updated in the UI. A welcome modal for the new brand added with "show once" logic persisted in localStorage.
Mid-journey surprises
Four things that weren't in the plan and changed the execution pace:
The Tab component had to bump to v2.1.0
During the main repo's migration, we discovered the Tab component had a non-trivial API change — not just styling, behavior. The change couldn't go in v2.0.0 without potentially breaking consumers who had already started migrating. The fix was to publish a v2.1.0 with the change, document it, and communicate it as a second migration step. Small in code, non-trivial in coordination.
CSS specificity conflicts with MUI
After applying the updated theme, CSS specificity conflicts surfaced in cases where app code had local overrides competing with the central theme's overrides. The previous theme (v1) was less aggressive in its overrides, so the conflicts weren't visible. The v2 theme, with a more contrasting palette and more MUI component overrides, made several of those conflicts become visible. It required a dedicated fix pass.
A layout broke and had to be reverted before the release
A card layout broke during the migration — specifically the grid distribution in a dashboard view. It wasn't a design system error, it was an interaction between the theme change and a layout that assumed certain MUI defaults. It was caught during the week 4 integration pass. The call was to revert that specific change, document it, and leave it out of the release. Better a slightly reduced scope than a visible bug in production on day one.
The v2 design system spec iterated during the migration
Several commits have the "resolve feedback" message — and that feedback came from the design team while the migration was already underway. The PRD said "the spec will be ready before execution." The reality is that seeing components rendered with the new theme surfaced adjustments that weren't visible in static mockups. Button spacing, heading font weight, the radius on certain cards. Each one was a small change, but together they represented several days of extra work spread across weeks 2 and 3.
Mobile fixes post-rebrand
The navbar collapse on mobile, the responsiveness of date pickers, and the avatar in dense mode needed dedicated fixes after applying the v2 theme. Not because the theme broke them — they were partially broken before — but because the visual contrast of the rebrand made the problems more visible. The rebrand acted as involuntary QA.
The major version bump as communication contract
There's a way of thinking about version numbers I find more useful than the standard semver definition: the version is a signal of how much attention the consumer needs to pay.
- A patch (1.0.x) says: something is fixed, you can update without reading anything.
- A minor (1.x.0) says: something is new, you probably don't have to change your code.
- A major (x.0.0) says: there are intentional changes that require your attention before updating.
In this release, the major didn't just serve as a technical barrier. It was an explicit promise to the teams consuming the packages: "when you see the v2.0.0 notification, don't auto-update. Read the migration guide. Coordinate with us. There's work on your side."
That promise was honored. No repo updated by accident. Every migration was a deliberate decision coordinated with that repo's team.
The difference between 9 and 26
There's a question worth asking: if the PRD documented 9 patterns and the reality was 26+, was the PRD wrong?
No. The PRD documented the changes visible from the system design perspective: which tokens change, which values get removed, which package API breaks. That's exactly what a PRD should capture at the planning stage.
The other 17+ patterns emerged from a different perspective: that of the code consuming the system. And that code doesn't live in the library monorepo — it lives in the application repos. To see those changes, you have to stand on the other side of the dependency graph.
The lesson isn't "the PRD should have been more exhaustive." It's that a PRD's breaking-change inventory is always a lower bound, not an upper bound. The upper bound is only known when you start executing.
The migration guide as a first-class deliverable
Part of the epic's Definition of Done was publishing a migration guide for external consumers. Not as courtesy documentation — as an active coordination tool.
The guide documented, for each breaking change:
- What changes in v2
- How to detect whether your code is affected
- The exact change you need to make
That turned 26+ change categories into an executable checklist. Instead of each consumer team discovering the changes by trial and error, they had a map. And the guide was written after executing the full migration — not before. That means every point in the guide was validated against real code, not assumptions.
Coordinating migration across 4 repositories
The plan's design was sequential: first the base packages (weeks 1–2), then the consumer apps (week 3), then integrated QA (week 4). In practice, weeks 3 and 4 overlapped, and the QA week ended up also being a fix week.
The biggest risk in multi-repo coordination isn't technical — it's communication. Consumer repos had their own sprints, their own in-flight PRs, their own priorities. Integrating a breaking change of this magnitude means that at some point someone is going to merge something that creates conflicts with the migration branch. And it happened: we had to resolve merge conflicts in at least two repos during QA week, because develop kept receiving changes while the migration branch was open.
The strategy we used to reduce that risk:
1. Long-lived feature branch per repo
Each repo had its own feat/design-system-v2 branch. Migration changes lived there, isolated from regular sprint work, until they were ready to merge.
2. Verification builds before every PR Every migration PR had to pass a full build. There was no way to merge code that didn't compile. This caught several CSS specificity conflicts and import errors before they reached develop.
3. Explicit dependency communication When the tokens package was published, the theme package was explicitly notified it could move forward. When the three base packages were published, consumer repos were notified they could start. The chain was respected.
4. Develop freeze before final merge In the two days before the release merge, the consumer repos' develops went into soft freeze — critical fixes only. That reduced the risk of last-minute conflicts. It didn't eliminate every conflict, but it reduced the surface enough that the remaining ones were manageable without time pressure.
5. Staggered publication, not simultaneous The three base packages weren't published in one command. First tokens, verification, then theme, verification, then components. Each publication included a manual smoke test in Storybook before approving the next layer. The extra time was worth it: the theme's smoke test caught an incorrect color override in a secondary component that would have otherwise reached the consumer repos.
What I learned
The number of breaking changes you anticipate is proportional to how well you know the actual state of your consumers. The PRD captured the changes visible from the architecture. The 17+ additional ones emerged from reading consumer repo code line by line, searching for hardcoded hex codes, and rendering the full product with the new theme applied. There's no substitute for that work, and there's no way to do it ahead of time — you can only do it once you have the new theme in hand.
The major version does its job if it's used with intent. It's not just semver — it's a coordination signal. Use it when the change requires the consumer to make an active decision.
The spec you have at the start isn't the spec you execute. In a visual rebrand, design keeps evolving as you see the actual rendered results. A Figma mockup and a component rendered in the browser with real data are two different things. Figma's visual space hides spacing inconsistencies that are immediately obvious in the product. That's not a process failure — it's the nature of visual work, and the plan has to leave room for those iterations.
Rollback has to be a first-class citizen in planning. The layout we reverted days before the release was an easy decision because we had margin and the change was isolated. It would have been a much harder decision under date pressure and with the change entangled with others. Isolating changes into small, well-bounded PRs isn't bureaucracy — it's the only way to keep control.
Design for reality, not for the happy path. The PRD had a mitigation plan for every identified risk. The problem wasn't that the risks materialized — it was that the most impactful risks weren't on the list. The CSS fixes, the broken layout, the spec changing during execution: none of them were documented risks. Leaving room for the unknown (in time, in capacity, in scope buffer) is what lets a release with 274 commits land alive.
Conclusion
274 commits, 50+ PRs, 4 repositories, 3 packages on v2.0.0, one package on a minor bump, and a release that hit production on May 11 with no critical incidents.
The number that matters most isn't 274. It's that none of the consumer repos updated by accident. That the layout that broke was caught before the release. That the 26+ breaking changes had documentation before they reached the consumer teams.
A breaking change at this scale doesn't get "managed" — it gets coordinated. The difference is in who has information, when they have it, and whether the plan has enough margin to absorb what wasn't anticipated.
The next post shifts angle completely: while the frontend was landing this release, in parallel I was coordinating the rebrand of every transactional email and backend document — with three teams that weren't mine and without a single requirements document...