274 commits, 50+ PRs, 4 paquetes: anatomía de un breaking change v2 que aterrizó vivo
El PRD documentaba 9 patrones de breaking changes. La realidad fueron 26+. Esto es lo que aprendí coordinando un major version bump a través de 4 repositorios y 3 paquetes simultáneos.
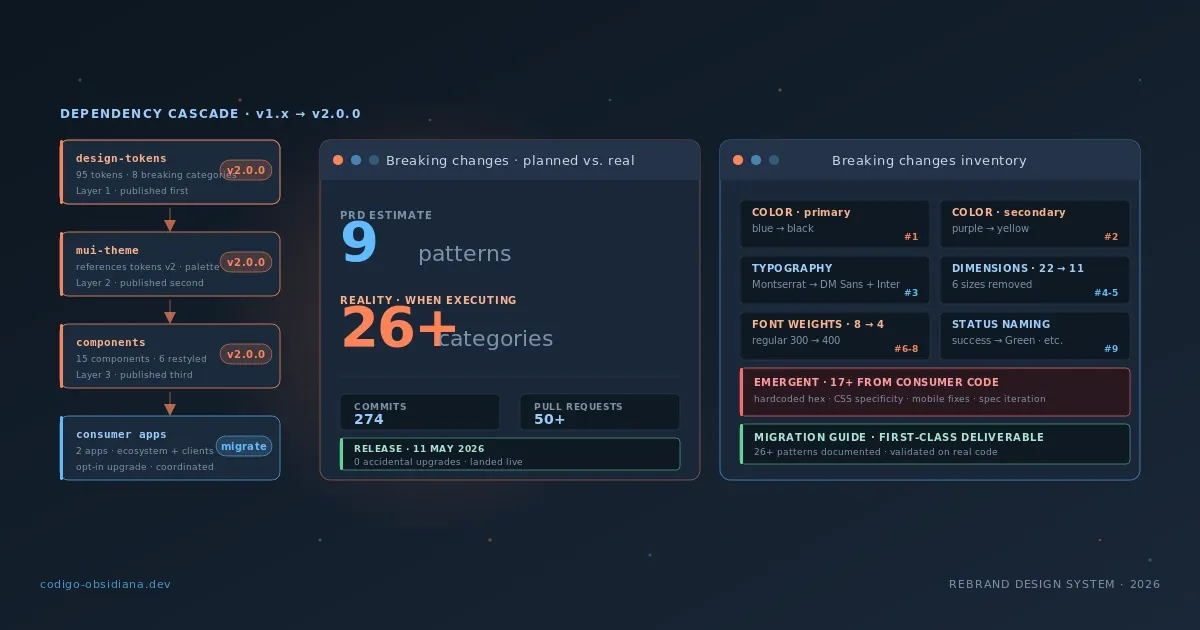
El 11 de mayo de 2026 hicimos merge de un feature branch con 274 commits, 50+ PRs y cambios en 4 repositorios simultáneos. El paquete de tokens llegó a v2.0.0. El paquete de tema llegó a v2.0.0. La librería de componentes llegó a v2.0.0. Y un cuarto paquete de assets escaló de 1.0.0 a 1.1.0.
El PRD que escribí en marzo documentaba 9 patrones de breaking changes. La realidad fueron 26+ categorías distintas.
Eso no fue un fallo de planeación. Fue una fotografía honesta de lo que se ve cuando pones un sistema real bajo la lupa de un cambio mayor.
La arquitectura de un breaking change en cadena
Un breaking change en un monorepo con dependencias anidadas no es un evento, es una secuencia. El orden importa tanto como el contenido.
En nuestro caso, el grafo de dependencias se veía así:
paquete de tokens v2.0.0
│
▼
paquete de tema v2.0.0
│
▼
librería de componentes v2.0.0
│
▼
┌───────┴────────┐
│ │
app principal app de clientes / ecosistema
Cada capa del grafo consume la anterior. Eso significa que si publicas el tema antes de tener los tokens estables, el tema construye sobre arena. Si actualizas los componentes antes de que el tema esté listo, cada componente override que toca el palette va a producir resultados incorrectos.
La regla operativa era simple: ninguna capa podía considerarse lista hasta que la capa debajo de ella estuviera publicada y verificada.
En la práctica, esto significó tres builds seriales en semanas distintas, y una sola semana de integración al final. Las apps consumidoras no tocaron los paquetes v2 hasta que los tres paquetes base estaban publicados y hubiéramos verificado que Storybook renderizaba correctamente.
Por qué el major version bump hace todo más manejable
Publicar como v2.0.0 (no como 1.2.0 ni como 1.1.0-beta) fue una decisión de comunicación, no solo de semver.
Con un major bump, el ecosistema de paquetes te da la red de seguridad por defecto: ^1.x.x no resuelve a 2.0.0. Ninguna app consumidora se actualiza sola. Nadie recibe el cambio sin pedirlo. La migración es opt-in y coordinada.
Si hubiéramos publicado como minor (1.x.0), la actualización habría sido automática en cualquier repo con ^1.0.0, y un cambio de palette primario de azul a negro habría aparecido en producción sin aviso. Con major, la barrera es intencional.
Lo que el plan capturó (y lo que no)
El PRD listaba 9 patrones de breaking changes. Son los que vi venir desde la arquitectura:
| # | Patrón documentado en el PRD |
|---|---|
| 1 | Color primario: azul → negro |
| 2 | Color secundario: morado → amarillo |
| 3 | Fuente: Montserrat → DM Sans + Inter |
| 4 | 6 dimensiones eliminadas (28–80px) |
| 5 | 2 espaciados eliminados (64px, 80px) |
| 6 | radio.4 (24px) eliminado |
| 7 | 4 pesos de fuente eliminados (100, 200, 800, 900) |
| 8 | weights.regular: 300 → 400 |
| 9 | Renombrado de grupos de status (success→Green, warning→Yellow, etc.) |
Lo que el PRD no podía ver era el estado real de los repos consumidores. Hasta que no empezamos a buscar activamente dónde se consumían los tokens, el tema y los componentes, no teníamos visibilidad sobre el delta completo.
El inventario real: 26+ categorías
Las 6 categorías que emergieron durante la ejecución:
1. Migraciones de componentes (5 sub-categorías) Button, Alert, TextField, Select/Autocomplete, DatePicker, Snackbar, Tabs: todos tenían implementaciones locales en los repos consumidores que debían ser reemplazadas por las versiones centralizadas de la librería. No era solo actualizar estilos — era consolidar código duplicado que había evolucionado de forma independiente.
2. Reemplazos de tokens y colores (6+ casos) Colores de marca hardcodeados en features de pagos, clientes y cobros. Cada uno fue un hallazgo manual durante la migración, no durante el audit. El audit de tokens que hicimos meses antes había capturado las referencias a variables de design tokens, pero no los hex codes escritos directamente en archivos de estilos. La búsqueda fue literal: grep por el hex del azul primario anterior, grep por el hex del morado secundario, y después revisión visual de los resultados. No hay forma elegante de hacerlo — solo hay que hacerlo.
3. Sistema tipográfico (4 casos) La pila de fuentes nueva se aplicó globalmente a través del tema, pero había flujos específicos (autenticación, registro) que tenían tokens de tipografía v1 referenciados directamente. Cada uno requería un reemplazo explícito.
4. Espaciado y layout (4+ casos)
El prop size en componentes de wallets fue removido. Constraints de min-width que el tema anterior imponía implícitamente quedaron expuestos al cambiar el tema. El navbar y sidebar necesitaban alineación con los nuevos Figma specs — cambios que no eran visibles en el design system en aislamiento, pero que eran obvios al ver el producto completo con el tema nuevo aplicado. Ninguno de estos era una violación de API documentada — eran efectos secundarios del cambio de tema que solo se revelan en contexto real de uso.
5. Migración de assets a CDN (6 casos)
Las animaciones Lottie fueron reemplazadas por SVGs estáticos más animación CSS — con ahorro medible en el bundle. Los íconos de estados de error migraron al CDN. El componente que controla el logo fue refactorizado para leer la variable de entorno VITE_CDN_URL. Se eliminaron 10 imágenes legacy sin uso activo.
6. Marca y dominio (2 casos) Referencias al dominio anterior actualizadas en la UI. Un modal de bienvenida al nuevo brand agregado con lógica de "mostrar una vez" persistida en localStorage.
Las sorpresas del medio camino
Cuatro cosas que no estaban en el plan y que cambiaron el ritmo de ejecución:
El componente Tab tuvo que subir a v2.1.0
Durante la migración del repo principal, descubrimos que el componente Tab tenía un cambio de API no trivial — no era solo estilo, era comportamiento. El cambio no podía ir en v2.0.0 sin potencialmente romper consumidores que ya habían empezado a migrar. La solución fue publicar un v2.1.0 con el cambio, documentarlo, y comunicarlo como un segundo paso de migración. Pequeño en código, no trivial en coordinación.
Conflictos de especificidad CSS con MUI
Después de aplicar el tema actualizado, surgieron conflictos de especificidad CSS en casos donde el código de las apps tenía overrides locales que competían con los overrides del tema central. El tema anterior (v1) tenía menos agresividad en sus overrides, así que los conflictos no eran visibles. El tema v2, con una paleta más contrastante y más overrides de componentes MUI, hizo que varios de esos conflictos se volvieran visibles. Requirió un pase dedicado de fixes.
Un layout se rompió y hubo que revertir antes del release
Un layout de tarjetas se rompió durante la migración — específicamente la distribución de grid en una vista de dashboard. No fue un error del design system, fue una interacción entre el cambio de tema y un layout que asumía ciertos defaults de MUI. Se detectó durante el pase de integración de la semana 4. La decisión fue revertir ese cambio puntual, documentarlo, y dejarlo fuera del release. Mejor un scope ligeramente reducido que un bug visible en producción el día 1.
El spec del design system v2 se iteró durante la migración
Varios commits tienen el mensaje "resolve feedback" — y ese feedback llegó del equipo de diseño mientras la migración ya estaba en curso. El PRD decía "la especificación estará lista antes de ejecutar". La realidad es que al ver los componentes renderizados con el nuevo tema, surgieron ajustes que no eran visibles en mockups estáticos. Espaciado de botones, peso de tipografía en headings, el radio de ciertos cards. Cada uno fue un cambio pequeño, pero en suma representaron varios días de trabajo extra distribuidos a lo largo de las semanas 2 y 3.
Fixes móviles post-rebrand
El collapse del navbar en mobile, la responsividad de los date pickers y el avatar en modo denso necesitaron fixes dedicados después de aplicar el tema v2. No porque el tema los rompiera — estaban parcialmente rotos antes — sino porque el contraste visual del rebrand hizo los problemas más visibles. El rebrand actuó como un QA involuntario.
El major version bump como contrato de comunicación
Hay una forma de pensar los números de versión que me parece más útil que la definición estándar de semver: la versión es una señal de cuánta atención necesita el consumidor.
- Un patch (1.0.x) dice: hay algo corregido, puedes actualizar sin leer nada.
- Un minor (1.x.0) dice: hay algo nuevo, probablemente no tienes que cambiar tu código.
- Un major (x.0.0) dice: hay cambios intencionales que requieren tu atención antes de actualizar.
En este release, el major no solo servía como barrera técnica. Era una promesa explícita a los equipos que consumen los paquetes: "cuando vean la notificación de v2.0.0, no actualicen automáticamente. Lean la guía de migración. Coordinen con nosotros. Hay trabajo de su lado."
Esa promesa fue respetada. Ningún repo se actualizó por accidente. Cada migración fue una decisión deliberada coordinada con el equipo de ese repo.
La diferencia entre 9 y 26
Hay una pregunta que vale la pena hacerse: si el PRD documentó 9 patrones y la realidad fueron 26+, ¿estuvo mal el PRD?
No. El PRD documentó los cambios que se podían ver desde la perspectiva del diseño del sistema: qué tokens cambian, qué valores se eliminan, qué API de paquete se rompe. Eso es exactamente lo que un PRD debería capturar en la etapa de planeación.
Los otros 17+ patrones emergieron de una perspectiva diferente: la del código que consume el sistema. Y ese código no vive en el monorepo de la librería — vive en los repos de las aplicaciones. Para ver esos cambios, hay que estar parado en el otro lado del grafo de dependencias.
La lección no es "el PRD debería haber sido más exhaustivo". Es que el inventario de breaking changes de un PRD es siempre un lower bound, no un upper bound. El upper bound solo se conoce cuando empiezas a ejecutar.
La guía de migración como entregable de primera clase
Parte de la Definition of Done del epic era publicar una guía de migración para consumidores externos. No como documentación de cortesía — como herramienta de coordinación activa.
La guía documentaba, por cada breaking change:
- Qué cambia en v2
- Cómo detectar si tu código está afectado
- El cambio exacto que hay que hacer
Eso convirtió 26+ categorías de cambios en un checklist ejecutable. En lugar de que cada equipo consumidor descubriera los cambios por prueba y error, tenían un mapa. Y la guía se escribió después de ejecutar la migración completa — no antes. Eso significa que cada punto de la guía fue validado en código real, no en supuestos.
Coordinando la migración en 4 repositorios
El diseño del plan era secuencial: primero los paquetes base (semanas 1–2), luego las apps consumidoras (semana 3), luego QA integrado (semana 4). En la práctica, las semanas 3 y 4 se solaparon, y la semana de QA terminó siendo también una semana de fixes.
El mayor riesgo en coordinación multi-repo no es técnico — es de comunicación. Los repos consumidores tenían sus propios sprints, sus propios PRs en vuelo, sus propias prioridades. Integrar un breaking change de esta magnitud significa que en algún punto alguien va a hacer un merge que genera conflictos con la rama de migración. Y en la práctica, pasó: hubo que resolver conflictos de merge en al menos dos repos durante la semana de QA, porque develop siguió recibiendo cambios mientras la rama de migración estaba abierta.
La estrategia que usamos para reducir ese riesgo:
1. Feature branch de larga vida en cada repo
Cada repo tenía su propia rama feat/design-system-v2. Los cambios de migración vivían ahí, aislados del trabajo del sprint normal, hasta que estaban listos para hacer merge.
2. Builds de verificación antes de cada PR Cada PR de migración tenía que pasar un build completo. No había forma de mergear código que no construyera. Esto detectó varios conflictos de especificidad CSS y errores de importación antes de que llegaran a develop.
3. Comunicación explícita de dependencias Cuando el paquete de tokens fue publicado, se avisó explícitamente que el paquete de tema podía avanzar. Cuando los tres paquetes base estuvieron publicados, se avisó que los repos consumidores podían empezar. La cadena fue respetada.
4. Freeze de develops antes del merge final En los dos días previos al merge del release, los develop de los repos consumidores entraron en soft freeze — solo fixes críticos. Eso redujo el riesgo de conflictos de última hora. No eliminó todos los conflictos, pero redujo la superficie lo suficiente para que los que quedaron fueran manejables sin presión de tiempo.
5. Publicación escalonada, no simultánea Los tres paquetes base no se publicaron en un solo comando. Primero tokens, verificación, luego tema, verificación, luego componentes. Cada publicación incluía un smoke test manual en Storybook antes de dar el OK para la siguiente capa. El tiempo extra valió: el smoke test del tema detectó un override de color incorrecto en un componente secundario que de otra forma hubiera llegado a los repos consumidores.
Lo que aprendí
El número de breaking changes que anticipas es proporcional a cuánto conoces el estado real de tus consumidores. El PRD capturó los cambios visibles desde la arquitectura. Los 17+ adicionales emergieron de leer código de repos consumidores línea por línea, buscar hex codes hardcodeados, y renderizar el producto completo con el tema nuevo aplicado. No hay sustituto para ese trabajo, y no hay forma de hacerlo antes de tiempo — solo puedes hacerlo cuando tienes el tema nuevo en mano.
La versión major hace su trabajo si se usa con intención. No es solo semver — es una señal de coordinación. Úsala cuando el cambio requiere que el consumidor tome una decisión activa.
El spec que tienes al inicio no es el spec que ejecutas. En un rebrand visual, el diseño sigue evolucionando mientras ves los resultados reales renderizados. Un mockup en Figma y un componente renderizado en browser con datos reales son dos cosas distintas. El espacio visual de Figma oculta inconsistencias de espaciado que son inmediatamente obvias en el producto. Eso no es falla del proceso — es la naturaleza del trabajo visual, y el plan tiene que tener margen para esas iteraciones.
El rollback tiene que ser un ciudadano de primera clase en la planeación. El layout que revertimos días antes del release fue una decisión fácil porque teníamos margen y el cambio estaba aislado. Hubiera sido una decisión mucho más difícil bajo presión de fecha y con el cambio entrelazado con otros. Aislar los cambios en PRs pequeños y bien delimitados no es burocracia — es la única forma de mantener control.
Diseña para la realidad, no para el happy path. El PRD tenía un plan de mitigación para cada riesgo identificado. El problema no fue que los riesgos se materializaran — fue que los riesgos más impactantes no estaban en la lista. Los fixes de CSS, el layout roto, el spec que cambia durante ejecución: ninguno era un riesgo documentado. Dejar espacio para lo desconocido (en tiempo, en capacidad, en scope buffer) es lo que permite que un release con 274 commits aterrice vivo.
Conclusión
274 commits, 50+ PRs, 4 repositorios, 3 paquetes en v2.0.0, un paquete en minor bump, y un release que llegó a producción el 11 de mayo sin incidentes críticos.
El número que más importa no es 274. Es que ninguno de los repos consumidores actualizó por accidente. Que el layout que se rompió fue detectado antes del release. Que los 26+ breaking changes tenían documentación antes de que llegaran a los equipos consumidores.
Un breaking change a esta escala no se "gestiona" — se coordina. La diferencia está en quién tiene información, cuándo la tiene, y si el plan tiene suficiente margen para absorber lo que no se anticipó.
El siguiente post cambia completamente de ángulo: mientras el frontend aterrizaba este release, en paralelo estaba coordinando el rebrand de todos los correos transaccionales y documentos del backend — con tres equipos que no eran el mío y sin un solo documento de requerimientos...